参考blog:深入浅出完整解析AIGC时代中GAN系列模型的前世今生与核心知识
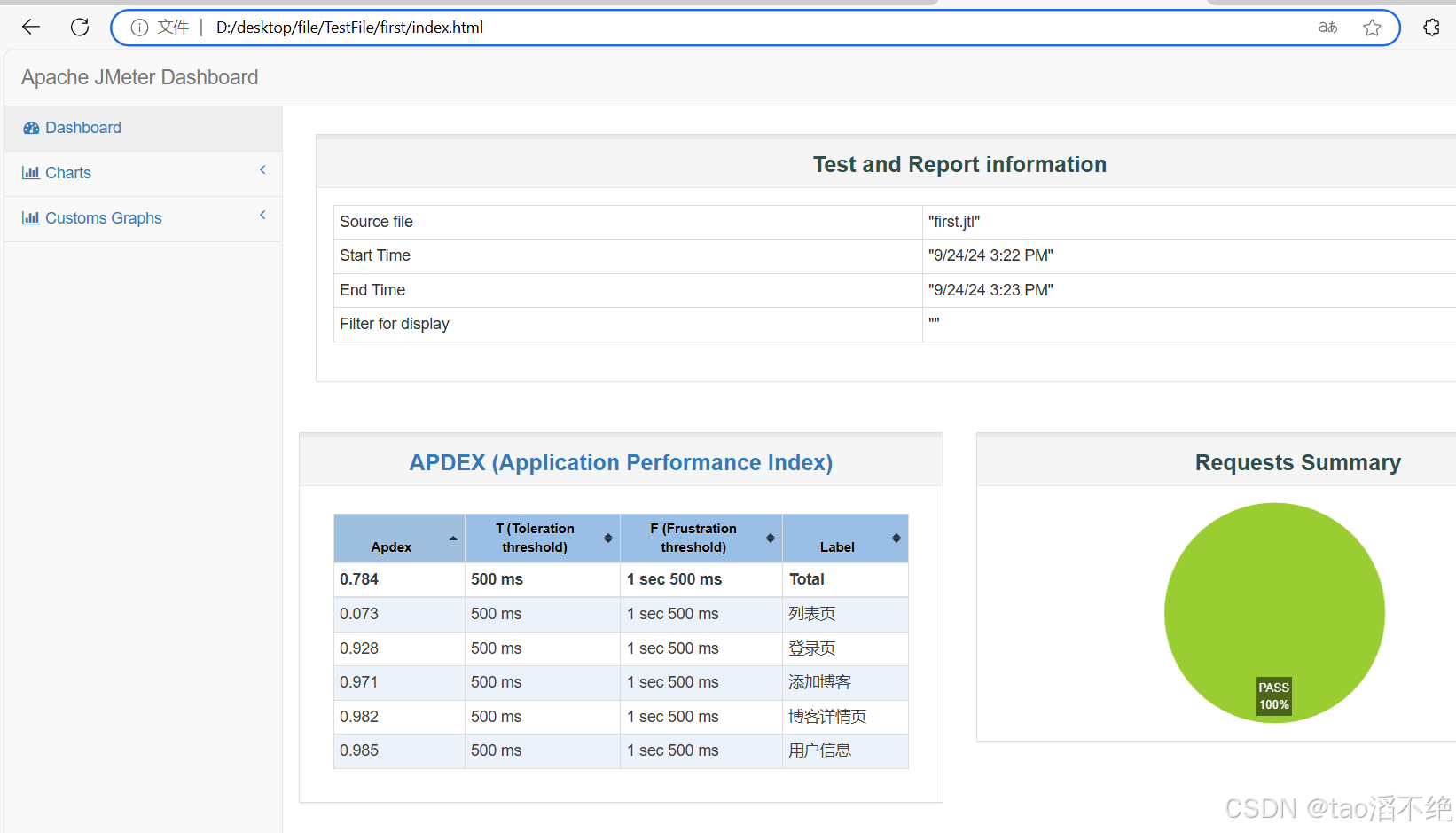
diffusion vs GAN 对比
生成速度
GAN架构通常比Diffusion架构更快,因为GAN只需要一次前向传播即可生成样本,而Diffusion模型需要多次采样迭代来逐步生成最终图像。同时Diffusion模型具有显著的优势,因为它们没有GAN常见的模式崩溃(mode collapse)问题。模式崩溃是指GAN在训练过程中生成多样性不足的问题,即模型可能仅生成少数几种类型的样本,而忽略数据集中其他类型的样本,本质原因是生成内容只需要骗过判别器就行,模型没必要承担更大风险去生成多样内容。相比之下,Diffusion模型能够更稳定地覆盖整个数据分布,从而生成更为多样化的样本。
拟合复杂数据分布
Diffusion模型相比于GAN更具优势,能够模拟更复杂且非线性的分布。GAN通常在特定单一类别的生成任务中表现出色,例如人脸生成,这使得它在特定场景下可以达到极高的生成质量。然而,GAN在处理包含多种不同类别的复杂数据集时,往往难以学习到所有类别的分布特征。Diffusion模型则能够更好地建模复杂、多样化的图像分布。然而,在连续性方面,Diffusion模型可能不如GAN。例如,在视频风格迁移的任务中,Diffusion模型生成的连续帧之间的关联性可能较弱,导致帧间关系差异较大。
可控编辑
以StyleGAN为代表的GAN模型,其生成器的输入是由噪声(noise)和潜在编码(Latent Code,通常表示为w)组成。潜在编码w的存在使得GAN在生成过程中具有更直观的可控性,可以通过调整低维空间中的编码来控制生成的高维数据。比如,GAN可以实现连续的插值操作,或者通过像DragGAN这样的技术来进行精细的图像编辑。与此不同的是,以Stable Diffusion为代表的Diffusion模型,其输入包括噪声潜在空间(noise latent space)和文本嵌入空间(text embedding space)。虽然文本嵌入可以引导生成内容,但其可控性相对w来说没有那么直接,特别是在需要精确控制生成图像的具体特征时。
训练数据要求
此外,Diffusion模型对训练数据的要求通常高于GAN。当前大多数Diffusion模型的训练需要高质量的配对数据(ground truth,GT)来确保模型能够学习到精确的映射关系。
GAN不仅可以用于生成任务,还可以作为其他任务的损失函数,例如用于图像翻译、超分辨率重建等领域,为这些任务提供有效的监督信号。
GAN模型的优势:
比起Stable Diffusion、Midjourney、DALL-E 3等AI绘画大模型,GAN更加轻量化,能够做到实时对图像进行优化生成与处理。
GAN能够很好的辅助Stable Diffusion、Midjourney、DALL-E 3等AI绘画大模型,完成一些模块化和局部的图像生成与处理工作,成为AI绘画工作流中的高性价比模型。
GAN中提取的低维度Latent特征对于语意解偶问题很有价值,这让GAN模型可以作为AIGC时代的AI绘画工作流的一部分,对生成图像进行局部编辑。
GAN在人脸等特征上的表现不错,可以作为AI绘画大模型的后处理模型。
避免GAN训练崩溃的一些经验总结
- 归一化图像输入到(-1,1)之间;Generator最后一层使用tanh激活函数 生成器的Loss采用:min (log
1-D)。因为原始的生成器Loss存在梯度消失问题;训练生成器的时候,考虑反转标签,real=fake, fake=real - 不要在均匀分布上采样,应该在高斯分布上采样
- 一个Mini-batch里面必须只有正样本,或者负样本。不要混在一起;如果用不了Batch
Norm,可以用Instance Norm - 避免稀疏梯度,即少用ReLU,MaxPool。可以用LeakyReLU替代ReLU,下采样可以用Average
Pooling或者Convolution + stride替代。上采样可以用PixelShuffle, ConvTranspose2d +
stride - 平滑标签或者给标签加噪声;平滑标签,即对于正样本,可以使用0.7-1.2的随机数替代;对于负样本,可以使用0-0.3的随机数替代。
- 给标签加噪声:即训练判别器的时候,随机翻转部分样本的标签。
- 如果可以,请用DCGAN或者混合模型:KL+GAN,VAE+GAN。
- 使用LSGAN,WGAN-GP
- Generator使用Adam,Discriminator使用SGD
- 尽快发现错误;比如:判别器Loss为0,说明训练失败了;如果生成器Loss稳步下降,说明判别器没发挥作用
- 不要试着通过比较生成器,判别器Loss的大小来解决训练过程中的模型坍塌问题。比如: While Loss D > Loss A:
Train D While Loss A > Loss D: Train A - 如果有标签,请尽量利用标签信息来训练
- 给判别器的输入加一些噪声,给G的每一层加一些人工噪声。 多训练判别器,尤其是加了噪声的时候
- 对于生成器,在训练,测试的时候使用Dropout
GAN基础
概览
GAN由生成器G和判别器D组成。其中,生成器主要负责生成样本数据,输入一般是由高斯分布随机采样得到的噪声Z。而判别器的主要职责是区分生成器生成的样本与gt(GroundTruth)样本,输入一般是gt样本与相应的生成样本,我们想要的是对gt样本输出的置信度越接近1越好,而对生成样本输出的置信度越接近0越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
- 生成器(Generator):
-
任务是生成尽可能接近真实数据的新数据。例如,在图像生成任务中,生成器试图创建新的图像,这些图像看起来像是从真实数据集中取出的。
-
它接收随机噪声作为输入,并将这个噪声映射到数据空间,产生新的数据实例。
- 判别器(Discriminator):
-
任务是区分输入数据是来自于真实数据集还是生成器产生的。
-
它接收真实数据或生成器产生的数据作为输入,并尝试判断这些数据是真是假。
GAN训练过程:
GAN的训练涉及到一个双方博弈的过程,其中生成器试图“欺骗”判别器,让判别器将其生成的假数据判断为真数据;而判别器则努力不被欺骗,准确地区分真假数据。训练过程中,生成器和判别器交替进行优化:
-
判别器训练:固定生成器,更新判别器的参数,提高其区分真实数据和生成数据的能力。
-
生成器训练:固定判别器,更新生成器的参数,提高生成数据的“真实性”,使得判别器更难以区分。
GAN的对抗生成思想主要由其目标函数实现,通过给定一个生成器G和一个判别器D,GAN的目标函数V(G, D)具体公式如下所示:

训练流程:

图中可以看出,将判别器损失函数离散化,其与交叉熵的形式一致,我们也可以说判别器的目标是最小化交叉熵损失。
GAN Inversion(GAN逆向)
原理:
GAN Inversion(GAN逆向)是指将一个已生成的图像或真实图像映射回GAN的潜在空间(latent space),从而找到该图像的潜在向量(latent vector)。这种技术在图像编辑、图像重建和特征提取等任务中有广泛应用。GAN逆向的核心思想是利用优化算法或神经网络模型找到一个潜在向量,使得GAN生成的图像尽可能接近给定的目标图像。
GAN Inversion(GAN逆向)的具体步骤:
 优化方法
优化方法

GAN Inversion的应用
-
图像编辑:
通过逆向找到图像的潜在向量后,可以在潜在空间中进行编辑(如加减潜在向量),生成新的图像。 -
图像重建:
将损坏或部分缺失的图像进行逆向,找到潜在向量后,通过生成器重建图像。 -
特征提取:
GAN逆向可以用于提取图像的高层特征,用于其他任务如分类、检索等。通过GAN逆向技术,我们可以利用GAN的生成能力来实现对图像的高效处理和分析。
Pix2Pix系列模型
Pix2Pix是一种基于条件生成对抗网络(cGAN)的图像翻译模型,专门用于将一种图像风格转换为另一种图像风格。该模型通过成对的图像进行训练,其中每对图像分别代表同一场景的两种不同风格或表示。目前PixPix广泛应用于风格迁移、图像修复、图像合成等任务。

cGAN介绍
条件生成对抗网络(cGAN)是 Pix2pix 的基础架构。传统的 GAN(生成对抗网络)包括一个生成器(Generator)和一个判别器(Discriminator),生成器从噪声分布中生成假样本,判别器则尝试区分真假样本。cGAN 则在此基础上加入了条件信息,使得生成过程不仅依赖于噪声,还依赖于特定的条件输入,从而引导生成器生成符合条件的样本。
Pix2pix对cGAN进行了重要改进:
-
输入条件的改变:在 Pix2pix 中,生成器不再单独输入噪声向量和条件信息,而是直接将一种风格的图像作为输入,生成与该图像配对的另一种风格的图像。这种方法极大地简化了图像翻译任务,因为它消除了单独设计噪声输入的需求,并直接利用原始图像作为条件信息。
-
对抗性损失与 L1 损失结合:Pix2pix 的损失函数不仅包括传统的 cGAN 对抗性损失,还引入了 L1 损失(或称为重构损失)。L1 损失通过计算生成图像与真实图像之间的像素差异,鼓励生成器生成与真实图像更加接近的结果。这种结合可以有效地平衡生成器的能力,使其不仅能够骗过判别器,还能生成与目标风格一致的高质量图像。
-
PatchGAN 判别器:为了适应图像翻译任务的特点,Pix2pix 使用了 PatchGAN 判别器。与传统判别器不同,PatchGAN 关注的是图像的局部区域(通常是 70×70 的图像块),而非整个图像。这种设计有助于判别器关注图像的局部结构和纹理,从而更好地评估生成图像的质量,尤其是在风格迁移任务中。
StyleGAN系列模型
StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
StyleGAN的网络结构包含两个部分,第一个是Mapping network,即下图 (b)中的左部分,由隐藏变量 z 生成中间隐藏变量 w的过程,这个 w 就是用来控制生成图像的style,即风格。 第二个是Synthesis network,它的作用是生成图像,创新之处在于给每一层子网络都喂了 A 和 B,A 是由 w 转换得到的仿射变换,用于控制生成图像的风格,B 是转换后的随机噪声,用于丰富生成图像的细节,即每个卷积层都能根据输入的A来调整"style"。整个网络结构还是保持了 PG-GAN (progressive growing GAN) 的结构。
此外,传统的GAN网络输入是一个随机变量或者隐藏变量 z,但是StyleGAN 将 z 单独用 mapping网络将z变换成w,再将w投喂给 Synthesis network的每一层,因此Synthesis network中最开始的输入变成了常数张量,见下图b中的Const 4x4x512。

StyleGAN V2 的任务是image generation,给定特定长度的向量,生成该向量对应的图像,是StyleGAN的升级版,解决了StyleGAN生成的伪像等问题。
相对于StyleGAN,StyleGAN V2其主要改进为:
- 生成的图像质量明显更好(FID分数更高、artifacts减少)
- 提出替代渐进式训练的新方法,牙齿、眼睛等细节更完美
- 改善了风格混合
- 更平滑的插值 训练速度更快
GigaGAN核心基础知识
GigaGAN有三个主要的特点:
推理速度快: 在0.13秒内生成512*512像素的图像。
能合成超高清图像: 可以在3.66秒内合成4k分辨率的超高分辨率图像。
具有可控的潜在向量空间: 被赋予了一个可控的、基于潜在的向量空间,可以用于可控图像合成应用,例如风格迁移、prompt插值和prompt混合等。
GigaGAN模型是迄今为止最大的GAN模型,一共有1B的参数量,可以说是AIGC时代的GAN大模型。
GigaGAN的生成器架构:

GigaGAN生成器由文本编码分支、样式映射网络、多尺度合成网络组成,并通过稳定注意力和自适应核选择进行增强。在文本编码分支中,我们首先使用预训练的CLIP模型和训练中持续更新参数的注意力层T来提取Text Embeddings。然后将Text Embeddings传递给样式映射网络M,以生成样式向量w(style vector),类似于StyleGAN的逻辑。接着合成网络使用样式代码作为调制,并使用文本嵌入作为注意力来生成图像金字塔。此外,GigaGAN引入了样本自适应核选择,基于输入的文本条件自适应地选择卷积核。
GigaGAN生成器的各个部分的内容:
-
文本编码分支:这个部分的任务是处理输入的文本Prompt,主要使用一个已经预训练好的CLIP模型把文本Prompt转换成Text Embeddings特征。同时还使用了一些学习的注意力层来更好地理解输入的文本。
-
样式映射网络:文本编码分支得到的Text Embeddings特征会被传递到样式映射网络中,它的工作是生成样式向量,类似于StyleGAN中的做法。这个样式向量会帮助我们决定最终生成图像的风格和特征。
-
多尺度合成网络:主要负责实际的图像生成过程。它使用样式向量作为调制器,从而影响生成图像的风格。同时它使用Text Embeddings特征作为注意力机制,确保生成的图像和输入的文本相符。它生成的是一个图像金字塔,表示图像在不同分辨率上的多个版本。
-
增强机制:(1)稳定注意力,确保注意力机制在生成图像时更加稳定和准确。自适应核选择(2),根据输入的文本内容,自适应地选择最合适的卷积核来处理图像。卷积核是生成图像时的一个重要工具,选择合适的卷积核可以提高图像质量。
GigaGAN判别器架构详解

GigaGAN的判别器由两个分支组成,用于处理图像和文本调节 t_D。文本分支对文本的处理与生成器类似(图 4)。图像分支接收一个图像金字塔,并对每个图像尺度进行独立预测。此外,预测是在下采样层的所有后续尺度上进行的,这使得它成为一个多尺度输入、多尺度输出(MS-I/O)的判别器。
上图展示的是 GigaGAN 的判别器(Discriminator)的结构。判别器是生成对抗网络(GAN)中至关重要的一部分,负责区分生成器(Generator)生成的图像与真实图像。在这个架构中,GigaGAN 的判别器使用了多尺度的输入方式,并结合了文本条件信息(text conditioning)来进行判别。下面Rocky将深入浅出地讲解这张图以及相关的文字内容。
在图像分支中接收输入的图像
,并生成一个图像金字塔(image pyramid)。图像金字塔将图像在不同尺度上进行下采样,产生多个分辨率版本。这些不同分辨率的图像用于判别器的多尺度输入。这些图像会被逐层输入判别器,判别器会对每个尺度的图像独立地进行判别和预测。通过对不同分辨率的图像进行处理,判别器能够更好地捕捉图像中的不同层次的特征。
生成图像金字塔后,进行了多尺度输出 (Multi-scale Output)。在上图的右侧,展示了多尺度输出的部分,每个输出层都标有
,表示该层进行的卷积(Convolutional)和自注意力(Self-attention)操作。多尺度输出意味着判别器不仅仅依赖于单一分辨率的图像,而是结合了多个尺度的信息来做出判别。这种方法有助于捕捉图像的全局和局部特征,从而提高判别的准确性。
上图中黄色的方块表示卷积操作,而灰色的方块表示自注意力操作。卷积操作负责提取图像的空间特征,如边缘、纹理等;自注意力操作则能够捕捉图像中的长距离依赖关系和全局上下文。这种组合方式使得判别器不仅可以关注图像的局部细节,还能理解更广泛的图像上下文。
每个尺度的图像都会产生独立的预测结果,这意味着判别器在不同尺度上分别做出判断,最终可能会对这些独立的结果进行综合,以做出最终的判别。这种多尺度、独立预测的方式确保了判别器可以同时关注图像的细节和整体结构,提高了对图像真实性的判断能力。
总的来说,GigaGAN的判别器设计充分利用了多尺度输入、卷积与自注意力的结合以及文本条件信息的引入,通过这些策略,判别器能够更全面、更准确地判断生成图像的真实性和相关性。这种设计不仅提升了模型的判别能力,还增强了模型的鲁棒性和训练效率。在实际应用中,这种判别器可以为生成高质量、符合特定描述的图像提供有力的支持。